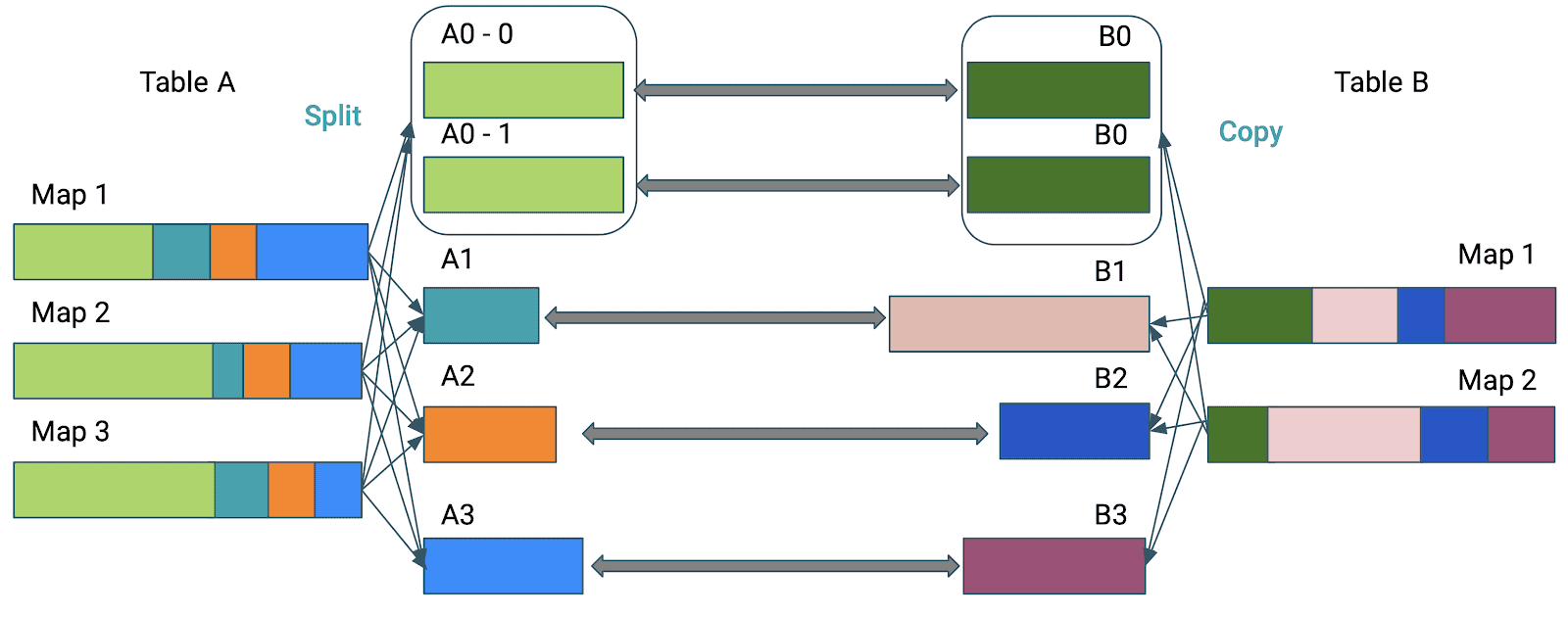
In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…
Apache Spark Performance is too hard. Let's make it easier
Spark Performance Optimization Series: #3. Shuffle, by Himansu Sekhar, road to data engineering
Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering
Optimizing Apache Spark Performance: Tackling Data Skew for Faster Big Data Processing, by VivekR
The 5S Spark Optimization Series, Part 2: Tackling Skew Optimization for Balanced Excellence!, by Chenglong Wu
Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai
Cranking the Voltage on Spark: Achieve Peak Performance with Optimization, by BlackRockEngineering